
灰度图 1通道
彩(RGB) 3通道
卷积层--->激励层--->卷积--->激励--->池化层--->全连接层(输出层)
输入层
卷积层-加权求和
提取图像中的局部特征
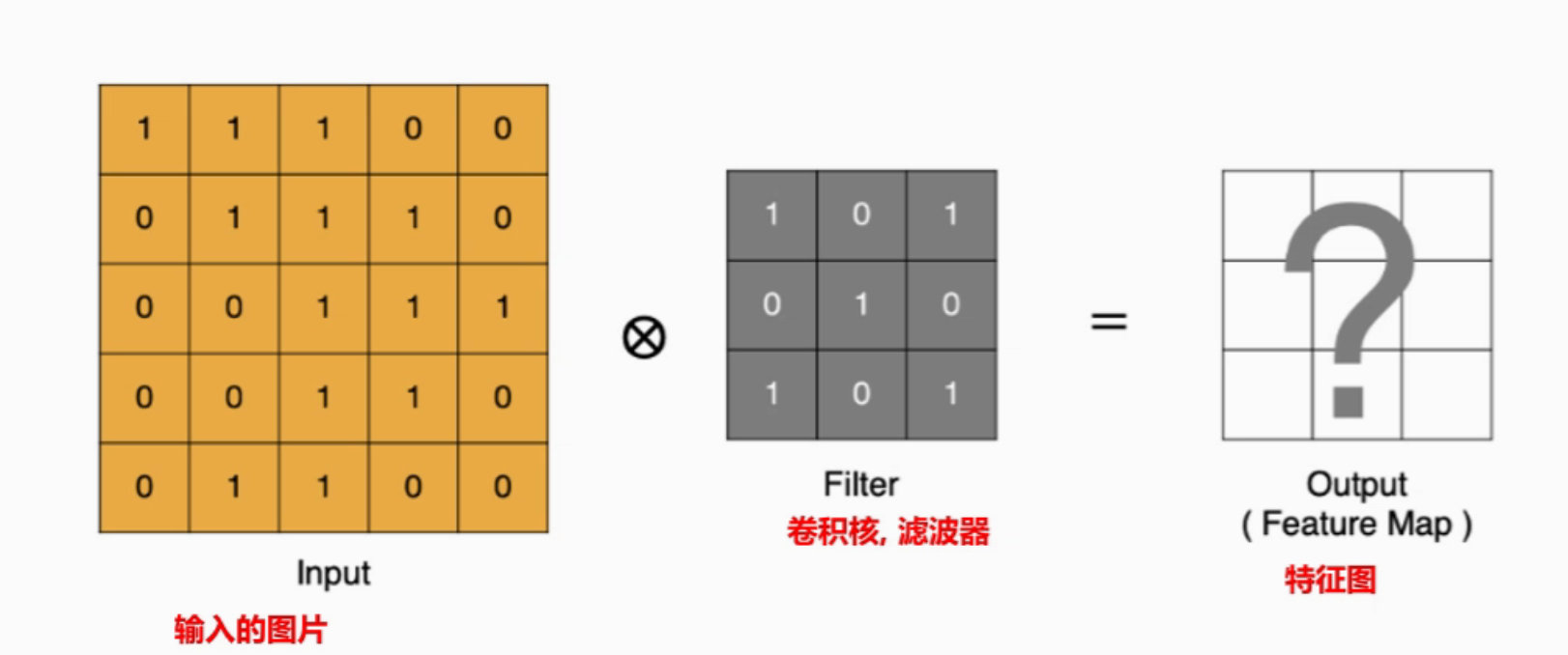
padding
padding(填充)操作用于卷积时 图像边缘的像素padding默认为1 为1就是加1圈0
padding解决了 可能 边缘信息丢失的问题
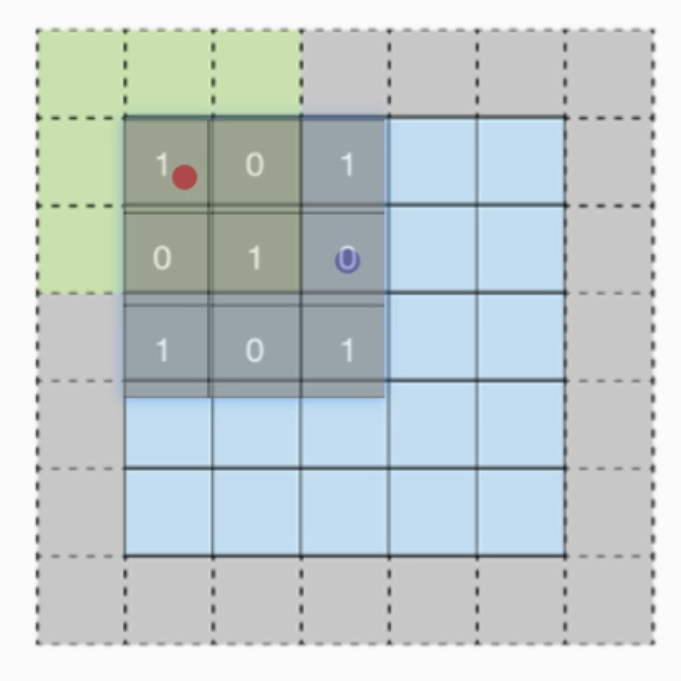
红点:未添加时 计算了 1*1次
蓝点:未添加时 计算了3*2次
Stride-卷积核移动的步长
特征图大小

W: 原图大小
F:卷积核大小
2P: padding*2S:Stride
默认向下取整
激励层-激活(Relu)
空
池化层-pool(max)
降维
池化层不会改变通道数量
不会它只会图片进行降维(图片压缩)
最大池化 与 平均池化
最大max:根据 卷积核取 最大
平均avg:根据 卷积核取 平均
池化矩阵---每一个=1个神经元
公式 同样适用
单通道与多通道池化 代码
import torch
import torch.nn as nn
#todo 1、 单通道池化 (1,3,3) 1channel 3*3px
def one_pooling():
x = torch.tensor([
[ # 3高 * 3宽
[1,2,3],
[4,5,6],
[7,8,9]
]
],dtype=torch.float32)
print(x.size())
#创建 池化层
pool_one = nn.MaxPool2d(kernel_size=2,stride=1,padding=0)
out_pool = pool_one(x)
print(out_pool.size())
# pool_one = nn.AvgPool2d(kernel_size=2,stride=1,padding=0)
#todo 2、 (3,3,3)
def mult_pooling():
x = torch.tensor([
[ # 3高 * 3宽
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
],
[ # 3高 * 3宽
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
],
[ # 3高 * 3宽
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]
], dtype=torch.float32)
# pool_mult = nn.MaxPool2d(kernel_size=2, stride=1, padding=0)
pool_mult = nn.AvgPool2d(kernel_size=2, stride=1, padding=0)
out_pool = pool_mult(x)
print(out_pool.size())
mult_pooling()全连接层
输出效果
案例代码
创建数据
import torch
import torch.nn as nn
from torchvision.datasets import CIFAR10 #encap get dataset
from torchvision.transforms import ToTensor#imge ---> Tensor
import torch.optim as optim
from torch.utils.data import DataLoader
from torchsummary import summary
BATCH_SIZE = 8
def create_dataset():
#alreading dataset
#parameter_one:dataset path parameter_two: if train? p_three:image--->tensorSet,
train_dataset = CIFAR10(root='./data',train=True,transform=ToTensor(),download=True)
test_dataset = CIFAR10(root='./data',train=False,transform=ToTensor(),download=True)
return train_dataset,test_dataset
x,y = create_dataset()
print(x.data.shape)
print(y.data.shape)
print(x.class_to_idx)#各分类的index info
print(x.data)#每个特征
print(x.targets[0])#特征对应的标签
绘图
plt.imshow(x.data[333]) #第333+1 个特征图片
plt.title(x.targets[333])#对应标签
plt.show()搭建CNN神经网络

class Image_model(nn.Module):
def __init__(self):
super().__init__()
#卷积层
self.conv1 = nn.Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
#池化层
self.pool1 = nn.MaxPool2d(2,2)
self.conv2 = nn.Conv2d(6,16,3,3)
self.pool1 = nn.MaxPool2d(2,2)
#全连接层
self.linear1 = nn.Linear(in_features=576,out_features=120)
self.linear2 = nn.Linear(120,84)
self.output = nn.Linear(84,10)
def forward(self,x):
#卷积-->激活-->池化--> 卷积2--->2激活--->2池化
x = self.pool1(torch.relu(self.conv1(x)))
x = self.pool2(torch.relu(self.conv2(x)))
#现在x为3维数据---->2维才可以处理
x = x.reshape(x.shape[0],-1)
#全连接层1,2,3:
x = torch.relu(self.linear1(x))
x = torch.relu(self.linear2(x))
x = self.output(x)预测 + 训练
def train_model(train_dataset):
train_loader = DataLoader(dataset=train_dataset,batch_size=BATCH_SIZE,shuffle=True)
model = Image_model()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(),lr=0.001)
epochs = 10
total_loss,total_sam,total_count = 0.0,0,0
corrent_p=0.0
for _ in range(epochs):
for x,y in train_loader:
model.train()
y_pre = model(x)
loss = criterion(y_pre,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss+=loss*len(y)
total_count += len(y)
print(total_loss/total_count)
corrent_p +=(torch.argmax(y_pre,dim=-1) == y).sum().item()
print(corrent_p)
torch.save(model.state_dict(),'./cnn_coing.pth')
print('The model successfly!')
def eval_model(test_dataset):
test_loader = DataLoader(dataset=test_dataset,batch_size=BATCH_SIZE,shuffle=False)
model = Image_model()
model.eval()
model.load_state_dict('./cnn_coing.pth')
total_correct = 0
total_samples = 0
for x,y in test_loader:
y_pre = model(x)
total_correct += (torch.argmax(y_pre,dim=-1)==y).sum()
total_samples+=len(y)
print(f'Acc:{total_correct/total_samples:.4f}')
主函数
if __name__ == '__main__':
train_dataset,test_dataset = create_dataset()
model = Image_model()
train_model(train_dataset)
test_model(test_dataset)
Comments NOTHING