
平台搭建和维护--->收集数据--->数据清理--->存储数据--->查询计算分析--->出图出报表
查询Pandas conda命令
conda list pandas #查询pandas当前版本
pip list | findstr pandas #查询是否有pandas包Pandas结构图
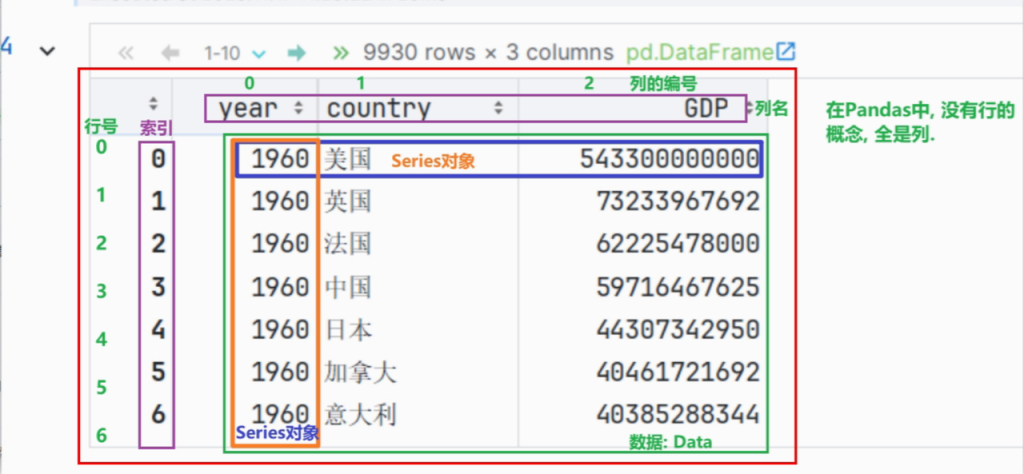
Series对象
series对象的创建
列表 + 默认索引
s1 = pd.Series([1,2,3,4])列表 + 自定义索引
s2 = pd.Series([1,2,3,4],index=['a','b','c','d'])元组方式
s3 = pd.Series(('a','b','c','d'),index=[1,2,3,4])字典方式
s4 = pd.Series({'a':1,'b':2,'c':3})numpyde NdArray 转换成Series对象
s5 = pd.Series(np.arange(1,6))DataFrame对象
DataFrame对象的创建
常用属性
df.index 索引
df.columns 列名
df.values 数据
de.shape 形状
df.shape[0] 行形状
df.shape[1] 列形状
df.size 元素的个数
df.T 转置
df.age方法
head()
tail()
describe(描述信息)#均值 std标准差 最大值 最小值
info 有几列 都是什么列 每列的元素类型df.set_index 与 df.reset_index
df.set_index:将列变为索引(提升到行索引)
数据维度:从 DataFrame → 仍是 DataFrame
效果:减少一列,该列变成索引
df.reset_index:将索引变为列(降级为普通列)
数据维度:从 DataFrame → 仍是 DataFrame
效果:增加一列,索引变成普通列
数据在"索引"和"列"之间的升降级转换。
-----------------------------------------------------
drop 参数:
默认:False
含义:是否丢弃索引(reset_index时)或原索引(set_index时)
inplace 参数:
默认:False
含义:是否原地修改(True=修改原对象,False=返回新对象
-----------------------------------------------------
df.set_index(['列名1','列名2'],inplace=False,drop=False)
df.reset_index(['列名1','列名2'],inplace=True,drop=True)DataFrame获取功能
loc(左右都包)
df.loc['行','列名']
df.loc['行':,'列名']
df.loc['行1':'行2','列名1':'列名2']
df.loc['行1','行2'],['列名1','列名2','列名2']
df.loc[:,['列名1','列名2']]iloc(包左 不包右)
df.iloc[行索引,列索引]
df.iloc[:,:3]
df.iloc[:,[0,1,2]]
df.iloc[[0,1,2],range(5)]
df.iloc[::2,::3]DataFrame 排序
sort_values
按照内容进行排序
sort_values('列名') 默认升序
sort_values('列名',ascending=False)
sort_values(['列名1','列名2'],ascending=[False,True]) 列1升序 列2降序sort_index
按照索引进行排序
df.sort_index() 升序
df.sort_index(ascending=False) 降序DataFrame 运算
加减
df['列名'] += 1
df['列名'] -= 1
----
df['列名'].add(1) #+1
df['列名'].sub(1) #-1逻辑运算
df['列名'] > 条件()
> < = ...
df[ (df['列名'] > 条件) & (df['列名'] < 条件) ]
& |query用法(通用)
query(表达式)
df.query('列名 > 条件 and 列名 < 条件')
or
df.query('列名 > 条件 & 列名 < 条件')
|isin用法
df[df['open'].isin([23.1,23.2]) ] 获取open值为23.1与23.2的行数据统计计算
| count | 统计空的个数 | |
| sum | 求和 | 默认axis=0列求和 axis=1行求和 |
| mean | 平均值 | |
| median | 中位数 | |
| min | 最小值 | |
| max | 最大值 | |
| mode | 频率最高 | |
| prod | 乘积 | |
| std | 标准差 | |
| var | 方差 | |
| idxmax | 最大索引 | |
| idxmin | 最小索引 | |
| abs | 绝对值 |
缺失值处理
df.replace('?', np.nan, inplace=True) #将?的非法值 转为空
df.dropna(axis='rows') 按行删除缺失值
df['列名'].fillna(df['同列名'].mean())#使用均值填充数据合并
concat() 可以水平/垂直合并
垂直:列名相同
pd.concat([df_one ,df_two....],axis=0)
df.merge()
pd.merge(df_one,df_two,on="left",how="inner")
pd.concat([df1, df2], axis='columns') 分组统计(*)
df.groupby(['字段1','字段2'...],as_index=False).agg({'要操作的列名':'聚合函数名','要操作的列名':'聚合函数名'...})
as_index=False 不用字段作为索引
df.groupby(['字段1','字段2'...])[['操作列名']].聚合函数 #两个[] 表示 返回dataframe对象
去重
df.drop_duplicates()
df.unique()
Comments NOTHING