
以前公式: W_new = W_old - 学习率 * 当前梯度
有时 梯度为0 此公式就不行了 会遇到鞍点 与 局部最小值
优化后公式:通过 移动指数加权平均 算梯度的时候,考虑历史+本次梯度(越远 权重以指数更新)越远权重越低(0.9**n)
以下是具体解决方案 momentum AdaGrad RMSProp Adam(考虑学习率+梯度)
具体优化方案
Momentum 优化器(与SGD --> 小模型-参数少)
Momentum 优化器在梯度下降中引入动量项(历史梯度的指数移动平均),加速收敛并减少震荡。
公式:W新 = W旧 - 学习率 * 移动指数加权平均 (它的系数一般为 0.9~0.99)
公式为:
st = β * s_t-1 + (1 - β) * gt
w新 = w旧 - 学习率 * st
解释:
st: 本次的移动指数加权 历史平均梯度
s_t-1: 上一次的移动指数加权 历史平均梯度
β: 调节权重系数, 值越大, 越参考历史平均梯度, (梯度优化方向)越平缓.
gt: 本次的梯度
是“历史信息”的权重,而 (1 − β) 是“当前新信息”的权重。
import torch
import torch.nn as nn
import torch.optim as optim
def demo_momentum():
w = torch.tensor([1.0],requires_grad=True,dtype=torch.float32)
loss = w**2/2.0#损失函数(这里是方便观察才写成这样)
optimizer = optim.SGD([w],lr=0.01,momentum=0.9)#动量因子系数
for i in range(3):#优化3次
loss = w ** 2 / 2.0#因为计算过一次梯度了,所以要再写一次
optimizer.zero_grad()
loss.sum().backward()
optimizer.step() #更新w
print(w,w.grad) #w.grad:取出当前计算的梯度
if __name__ == '__main__':
demo_momentum()AdaGrad 优化器(稀疏数据-0 1 多)
累计平方梯度
公式:W新=W旧 - update_学习率 * 累计平方梯度
update_学习率 :lr = lr/(sqrt(st)+小常数)
st = s_t + gt²(最小二乘) 累计平方梯度
s_t 为上一次的梯度
gt 为本次梯度
st 为累计平方梯度
小常数:1的-10次方 0.00....1
optimizer = optim.Adagrad([w],lr=0.01)RMSProp 优化器(稀疏数据-0 1 多)
指数加权累计平方梯度
st = β * s_t-1 +(1-β)*gt²
lr = lr/(sqrt(st) + 小常数)
解释:
st: 本次的移动指数加权 累计平方梯度
s_t-1: 上一次的移动指数加权 累计平方梯度
w新 = w旧 - update_学习率 * gt²
Adam 优化器(--->复杂大量数据)
公式为:
step1: 计算一阶 和 二阶矩估计
小常数: 1e-10
mt = β1 * m_t-1 + (1 - β1) * gt 结合了 动量法的操作 -> 一阶矩估计
st = β2 * s_t-1 + (1 - β2) * gt² 结合了 RMSProp的操作 -> 二阶矩估计
step2: 对上述的 矩估计进行 修正
mt^ = mt / (1 - β1 ** t)
st^ = st / (1 - β2 ** t)
step3: 计算学习率
lr = lr / (sqrt(st^) + 小常数)
w新 = w旧 - update_学习率lr * 优化后的梯度mt^
optimizer = optim.Adam([w],lr=0.01,betas=(0.9,0.99))
四者关系总结
| 优化器 | 可视为... | 核心贡献 |
| Momentum | 基础速度优化器-优化梯度 | 引入历史梯度平均形成动量 |
| AdaGrad | 第一代自适应学习率-优化学习率 | 累积梯度平方反比调整学习率 |
| RMSProp | AdaGrad改进版-优化学习率 | 指数移动平均解决衰减问题 |
| Adam | Momentum + RMSProp + 偏置校正 | 结合一阶矩和二阶矩估计的最流行优化器 |
学习率衰减
固定间隔
可以设置 间隔n轮 调整一次学习率 lr = lr * gama
import torch
import torch.optim as optim
# todo 1. 演示 固定间隔学习率优化
def dm01_fixed_interval_lr_optim():
# 1. 定义变量, 记录: 训练的轮数, (初始的)学习率, 每轮的迭代次数(即: 每轮迭代多少批)
epochs, lr, iteration = 200, 0.1, 10
# 2. 定义变量, 记录: 真实值.
y_true = torch.tensor([0], dtype=torch.float32)
# 3. 定义变量, 记录: x(特征), x(权重)
x = torch.tensor([1.0], dtype=torch.float32)
w = torch.tensor([1.0], dtype=torch.float32, requires_grad=True) # 自动微分(求导)
# 4. 定义变量, 记录: 优化器(采用 动量法)
optimizer = optim.SGD([w], lr=lr, momentum=0.9)
# 5. 定义学习率优化策略
# 思路1: 固定间隔学习率优化
# 参1: (要进行学习率优化的)优化器对象, 参2: 优化间隔(这里50轮), 参3: 学习率调整系数
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.5) # 公式为: lr = lr * gamma
# 6. 定义变量, 记录: 所有的轮数 以及 每轮的学习率.
epochs_list, lr_list = [], []
# 7. 具体的训练过程.
# 7.1 遍历轮数, 表示每轮具体的训练过程.
for epoch in range(epochs):
# 7.2 添加(当前的)轮数 和 本轮的学习率到 列表中.
epochs_list.append(epoch) # [0, 1, 2, 3....50, 51, ....101, 102... 150, 151...199]
lr_list.append(scheduler.get_last_lr()) # [[0.1], [0.1]...[0.05],....[0.025].....[0.0125].....]
# 7.3 遍历迭代次数, 迭代次数为10, 表示每轮迭代10批数据.
for i in range(iteration):
# 7.3.1 计算预测值.
y_pred = w * x
# 7.3.2 计算损失.
loss = (y_pred - y_true) ** 2
# 7.4.3 反向传播更新参数: 梯度清零 + 损失求导 + 参数更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 7.4 走到这里, 说明本轮训练完毕. 更新学习率
scheduler.step()等间隔
scheduler = optim.lr_scheduler.MultiStepLR(optimizer,milestones=[30,50,60], gamma=0.5) 指数间隔
scheduler = optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.5)正则化方法
DropOut 随机失活 ---> (一般与BN一起使用)
nn.dropout(p=?)
练时随机扔掉一些神经元 → 防过拟合 → 提升泛化
加权求和->激活函数->随机失活(先算再决定失活) 未被失活的神经元 进行 1/(1-p)缩放
随机失活概率p:0.2~0.5 (针对过拟合)
在训练时(model.train) 随机屏蔽神经元 测试不起作用(model.eval)
#-随机失活 过拟合
import torch
import torch.nn as nn
x = torch.randint(1,10,(1,4),dtype=torch.float32)
linear1 = nn.Linear(4,5)
x = linear1(x)
x = torch.relu(x)
print(f'失活前:{x}')
dp = nn.Dropout(0.5)
x = dp(x)
print(f"失活后{x}")BN 批量归一化
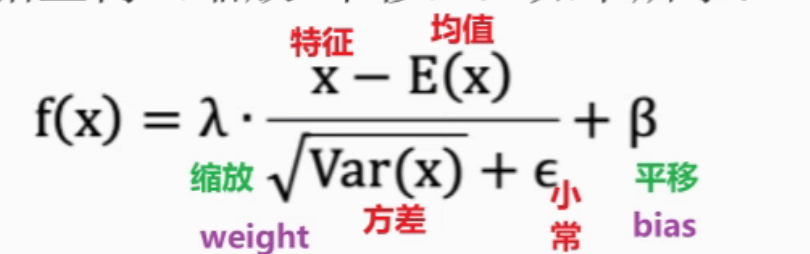
为什么有BN
OpenCV用的多
深度神经网络一般处理的都是大数据集,且都是分批处理的
如果批次之间的差异比较大 可能导致模型参数需大范围调整 从而迭代速度会变慢
训练效果会变差 可能会发生梯度震荡与爆炸
解决方案:对批次进行归一化(底层:标准化)处理,如sigmoid() 映射到[-3,3]之间 效果明显
弊端:归一化后 差异特征会缩小 或 丢失
解决:我们可以通过缩放(w) + 平移(b) 找补
import torch
import torch.nn as nn
bn_2d = nn.BatchNorm2d(2,eps=1e-5,momentum=0.1,affine=True)
#参1:2个通道 参2:防止分母为0 参3:动量法 参4:归一化后是否缩放与平移
input = torch.randn(1,2,3,4)
#1张图片 2个通道 3px高 4px宽
print("input--->",input)
output = bn_2d(input)
print('output--->',output)
print(output.size())
print(bn_2d.weight)
print(bn_2d.bias)
Comments NOTHING