
代码
"""
案例:
搭建神经网络(重要)
步骤:
1. 定义1个类 继承 nn.Module
2. 重写两个方法:
step1: __init__() 初始化方法
动作1: 初始化父类成员
动作2: 搭建神经网络层 -> 隐藏层, 输出层
step2: forward() 前向传播方法
会被自动调用, 算出最终结果.
3. 模型测试
搞一组数据, 传入上述的模型, 看看模型处理结果即可.
扩展:
torchsummary包下的summary模块 -> 可以查看模型的参数.
"""
# 导包
import torch # 包含了张量的各种处理
import torch.nn as nn # 封装了神经网络层, 损失函数, 激活函数...
from torchsummary import summary # 模型参数查看, 需安装 pip install torchsummary
# todo 1. 搭建神经网络
# 1. 定义1个类 继承 nn.Module
class ModelDemo(nn.Module):
# 2. 重写init初始化方法, 完成: 父类初始化, 搭建神经网络层
def __init__(self):
# 2.1 初始化父类成员
super().__init__()
# 2.2 搭建神经网络层
# 隐藏层1, 输入特征3, 输出特征3
self.linear1 = nn.Linear(3, 3)
# 隐藏层2, 输入特征3, 输出特征2
self.linear2 = nn.Linear(3, 2)
# 输出层, 输入特征2, 输出特征2
self.output = nn.Linear(2, 2)
# 2.3 完成隐藏层的参数初始化.
# 初始化隐藏层1的 权重矩阵
nn.init.xavier_normal_(self.linear1.weight)
# 初始化隐藏层1的 偏置矩阵
nn.init.zeros_(self.linear1.bias)
# 初始化隐藏层2的 权重矩阵
nn.init.kaiming_normal_(self.linear2.weight)
# 初始化隐藏层2的 偏置矩阵
nn.init.zeros_(self.linear2.bias)
# 3. 重写forward() 前向传播方法
def forward(self, x): # x就是输入的特征
# x(输入的特征) 要经过隐藏层1 -> 隐藏层2 -> 输出层的处理
# 3.1 隐藏层1的处理, 每个神经元 = 加权求和, 激活函数.
# 分解版写法.
# x = self.linear1(x)
# x = torch.sigmoid(x)
# 合并写法
x = torch.sigmoid(self.linear1(x))
# 3.2 隐藏层2的处理
x = torch.relu(self.linear2(x))
# 3.3 输出层的处理
# 参1: 输入特征(经过所有隐藏层和输出层处理后的结果), 参2: 计算的逻辑, 参数dim=-1, 表示最后一维进行计算.
x = torch.softmax(self.output(x), dim=-1)
# 3.4 返回处理结果
return x
# todo 2. 测试上述搭建的神经网络
if __name__ == '__main__':
# 1. 创建神经网络模型
model = ModelDemo()
# 2. 创建数据集, 随机生成.
# 输入特征: 5行3列(一批次有5条数据, 每条数据有3个特征)
data = torch.randn(5, 3)
# 3. 模型测试
# 底层会自动调用模型的forward()方法, 进行前向传播.
output = model(data)
print(f'模型的输出结果为: {output}')
print(' =.= ' * 5)
# 4. 查看模型的参数
# 写法1
# 参1: 模型对象, 参3: 输入特征维度, 参4: 批次大小.
# summary(model, (3, ), 5)
# 写法2:
# 参1: 模型对象, 参2: 输入特征维度.
summary(model, (5, 3))
# 5. 查看模型具体的参数(都有哪些)
for name, param in model.named_parameters():
print(f'参数名称: {name}, 参数: {param}')
损失函数
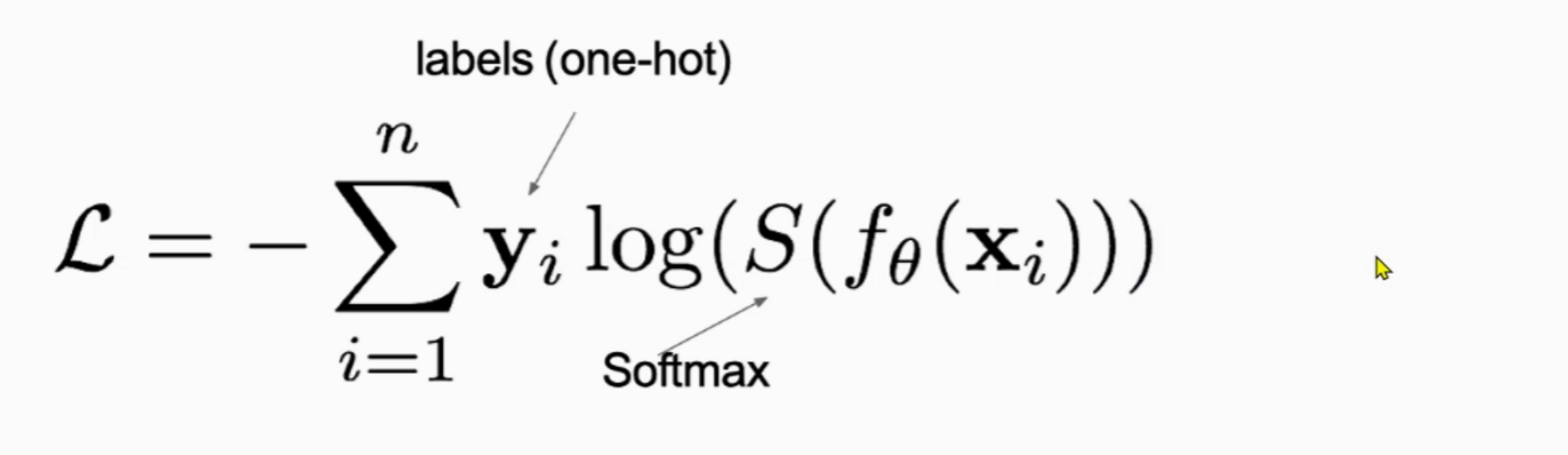
分类
二分类交叉熵损失BCELoss
多分类交叉熵损失CrossEntropyLoss
多分类交叉熵损失函数
计算: -Σ样本的真实概率*log(预测概率)
import torch
import torch.nn as nn
#1、表真实值数据#step1: 独热编码处理 必须 浮点型
# y_true = torch.tensor([[0,1,0],[0,0,1]],dtype=torch.float32)
#step2:索引值 必须 整数
y_true = torch.tensor([1,2],dtype=torch.int64)
#2、表预测值数据(预测概率)
y_pred = torch.tensor([[0.2,0.6,0.2],[0.1,0.8,0.1]],dtype=torch.float32)
#后续可以算反向传播更新梯度(推荐)
#y_pred = torch.tensor([[0.2,0.6,0.2],[0.1,0.8,0.1]],dtype=torch.float32,requires_grad=True)
criterion = nn.CrossEntropyLoss()
print(criterion(y_pred,y_true))二分类交叉熵损失BCELoss

计算:-真实概率*log(预测概率) - (1-真实)*log(1-预测)
import torch
import torch.nn as nn
y_true = torch.tensor([0,1,0],dtype=torch.float64)
y_pred = torch.tensor([0.2,0.6,0.2],dtype=torch.float64)
criterion = nn.BCELoss()
print(criterion(y_pred,y_true))回归
MSEMAE SmoothL1(分段函数整合了MSE和MAE)
MAE-nn.L1loss()
也叫L1loss 类似机器学习L1正则化(0点不可导)
导致:MAE损失函数不平滑,可能会越过极小值
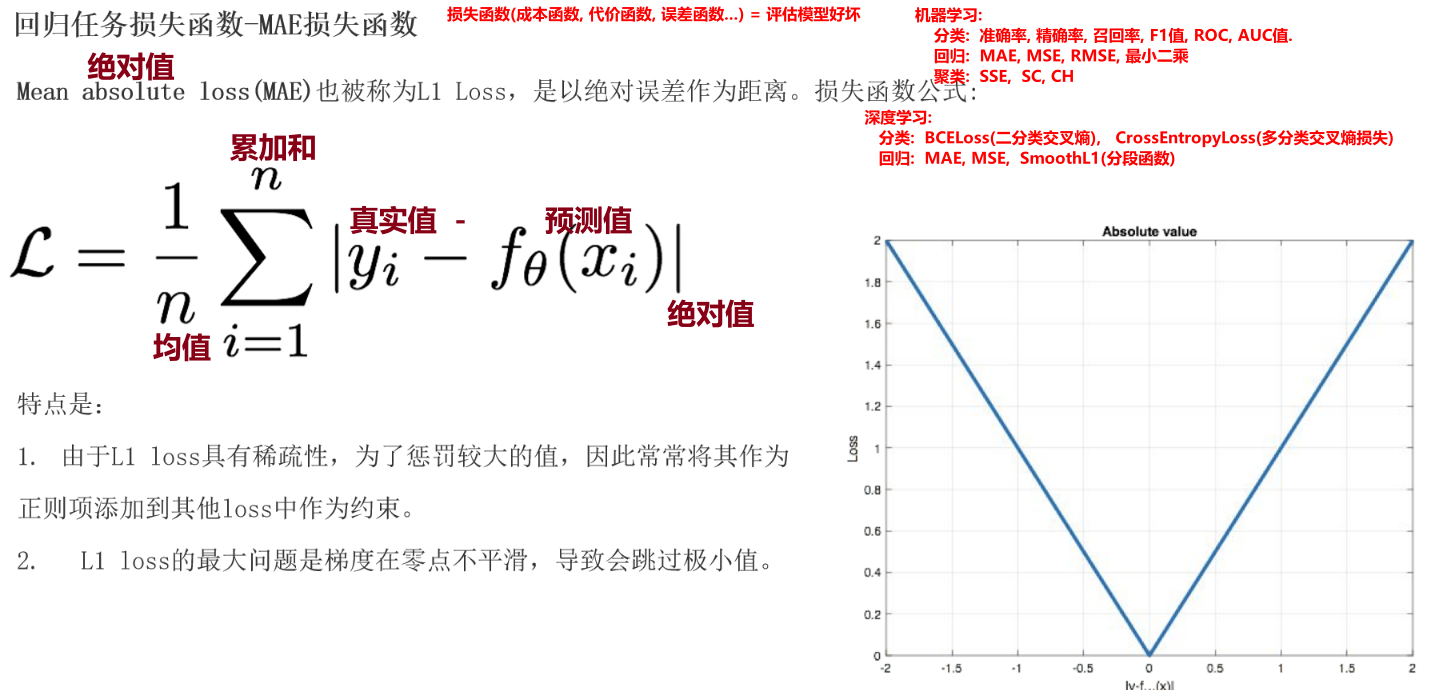
MSE-MSELoss()
欧式距离-均方误差
也叫L2loss, 类似于机器学习L2 权重只会趋向于0
弊端:如何误差特别大的情况下,可能出现梯度爆炸
MSE一般不单独使用,而是用作其他函数的正则化项
SmoothL1-nn.SmoothL1Loss()
L1(MAE) + L2(MSE) 的结合
在L1中加入平滑系数
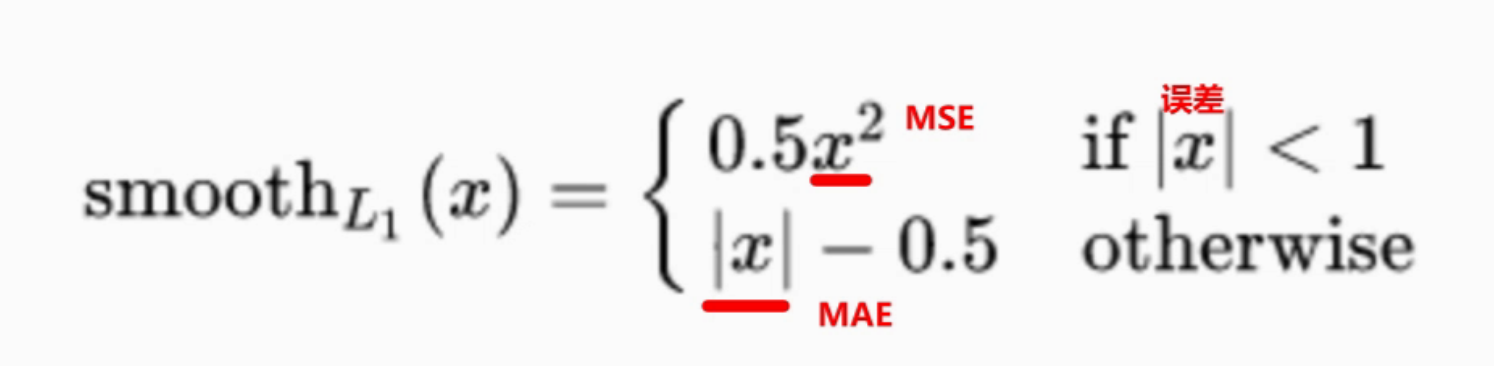
Comments NOTHING