
Sigmoid
会把结果映射到[0, 1]区间, 求导范围是: [0, 0.25], (特征)值在[-6, 6]之间效果明显, 在[-3, 3]效率较高. 应用场景: 浅层神经网络(不超过5层), 否则容易造成梯度消失. 一般用于 输出层的二分类 场景.
# 导包
import torch
import matplotlib.pyplot as plt
# 解决中文乱码问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# todo 1. 绘制Sigmoid函数图像
# 1. 创建画布
fig, ax = plt.subplots(1, 2) # 1行2列
# 2. 准备数据
# x轴: -20 ~ 20的等差数列
x = torch.linspace(-20, 20, 1000)
# y轴: x轴值经过sigmoid()激活函数处理后的结果.
y = torch.sigmoid(x)
# 3. 具体的绘图动作.
ax[0].plot(x, y)
ax[0].set_title('Sigmoid激活函数')
ax[0].grid()
# todo 2. 绘制Sigmoid函数的导数图像
# 1. 准备数据
# x轴: -20 ~ 20的等差数列
x = torch.linspace(-20, 20, 1000, requires_grad=True) # 启动自动求导(自动微分).
# y轴: Sigmoid()激活函数的导数结果.
# 2. 自动微分求导即可.
torch.sigmoid(x).sum().backward() # 求导必须是标量.
# 3. 具体的绘图动作.
# 参1: x轴数据(激活函数的输入结果), 参2: y轴数据(激活函数的导数结果)
ax[1].plot(x.detach(), x.grad)
ax[1].grid()
ax[1].set_title('Sigmoid导数图像')
# 4. 具体的绘图动作.
plt.show()
Tanh
既考虑正样本, 也考虑负样本.
会把结果映射到[-1, 1]区间, 求导范围是: [0, 1], (特征)值在[-3, 3]之间效果明显, 在[-1, 1]效率较高.
应用场景: 浅层神经网络(不超过5层), 否则容易造成梯度消失. 一般用于 (浅层神经网络)的隐藏层.
细节:
你运行如下的代码, 可能会出现OMP错误, 原因是因为: torch模块 和 Matplotlib模块的 libiomp5md.dll文件冲突了.
解决方案是: 删除 torch模块下的 libiomp5md.dll文件.
# 导包
import torch
import matplotlib.pyplot as plt
# 解决中文乱码问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# todo 1. 绘制tanh函数图像
# 1. 创建画布
fig, ax = plt.subplots(1, 2) # 1行2列
# 2. 准备数据
# x轴: -20 ~ 20的等差数列
x = torch.linspace(-20, 20, 1000)
# y轴: x轴值经过tanh()激活函数处理后的结果.
y = torch.tanh(x)
# 3. 具体的绘图动作.
ax[0].plot(x, y)
ax[0].set_title('tanh激活函数')
ax[0].grid()
# todo 2. 绘制tanh函数的导数图像
# 1. 准备数据
# x轴: -20 ~ 20的等差数列
x = torch.linspace(-20, 20, 1000, requires_grad=True) # 启动自动求导(自动微分).
# y轴: tanh()激活函数的导数结果.
# 2. 自动微分求导即可.
torch.tanh(x).sum().backward() # 求导必须是标量.
# 3. 具体的绘图动作.
# 参1: x轴数据(激活函数的输入结果), 参2: y轴数据(激活函数的导数结果)
ax[1].plot(x.detach(), x.grad)
ax[1].grid()
ax[1].set_title('tanh导数图像')
# 4. 具体的绘图动作.
plt.show()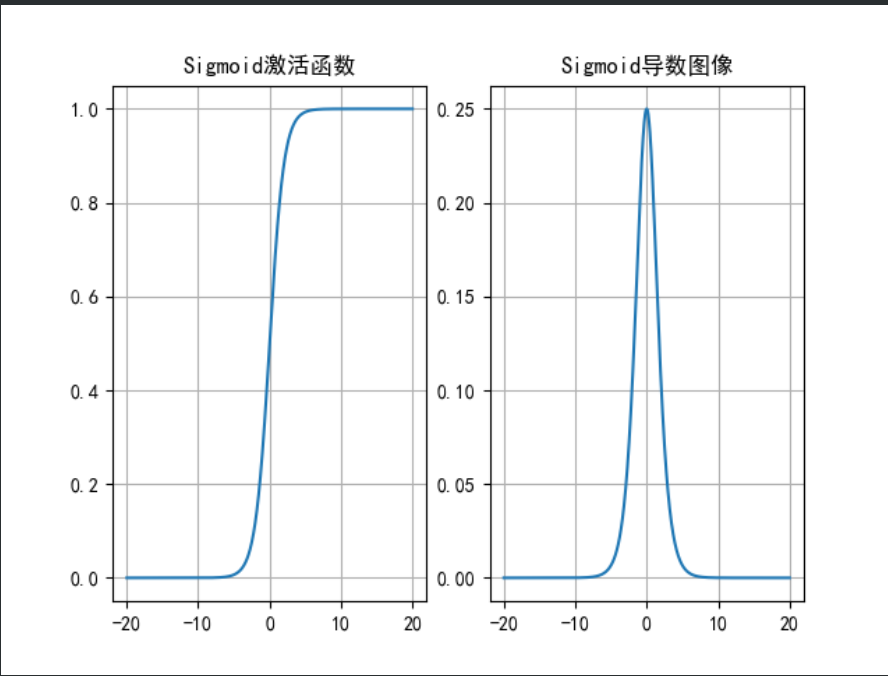
Relu
只考虑正样本 会使一部分神经元变为0 防止过拟合
求导范围为: 0 或 1,计算量小模型更新更快
梯度变为0的时候,会导致 神经元死亡
变形版:leakRelu、PRelu (考虑正负样本)
import torch
import matplotlib.pyplot as plt
# 解决中文乱码问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# todo 1. 绘制relu函数图像
# 1. 创建画布
fig, ax = plt.subplots(1, 2) # 1行2列
# 2. 准备数据
# x轴: -20 ~ 20的等差数列
x = torch.linspace(-20, 20, 1000)
# y轴: x轴值经过relu()激活函数处理后的结果.
y = torch.relu(x)
# 3. 具体的绘图动作.
ax[0].plot(x, y)
ax[0].set_title('relu激活函数')
ax[0].grid()
# todo 2. 绘制relu函数的导数图像
# 1. 准备数据
# x轴: -20 ~ 20的等差数列
x = torch.linspace(-20, 20, 1000, requires_grad=True) # 启动自动求导(自动微分).
# y轴: relu()激活函数的导数结果.
# 2. 自动微分求导即可.
torch.relu(x).sum().backward() # 求导必须是标量.
# 3. 具体的绘图动作.
# 参1: x轴数据(激活函数的输入结果), 参2: y轴数据(激活函数的导数结果)
ax[1].plot(x.detach(), x.grad)
ax[1].grid()
ax[1].set_title('relu导数图像')
# 4. 具体的绘图动作.
plt.show()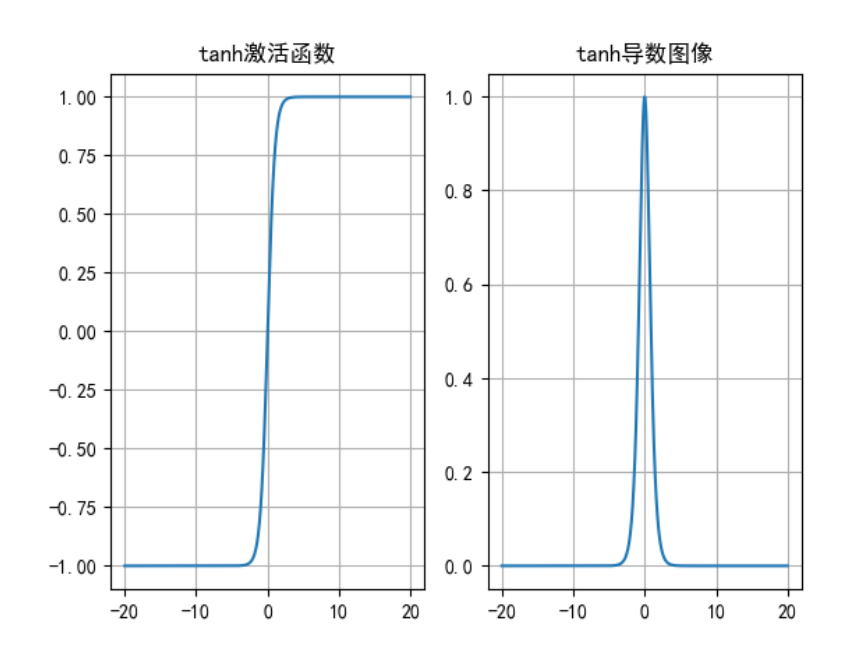
Softmax
考虑 正负
将多分类的结果以概率展现
最终分类结果:概率最大的一类 (所有的概率相加=1)
# 导包
import torch
# 1. 创建张量, 模拟: 样本的特征
scores = torch.tensor([0.2, 0.02, 0.15, 0.15, 1.3, 0.5, 0.06, 1.1, 0.05, 3.75])
# 2. 计算概率, dim = 0,按行计算
probabilities = torch.softmax(scores, dim=0) # 概率和为1, 最终选取概率最大的分类作为结果分类
# 3. 打印结果
print(probabilities)
# 扩展, 看看就行了, 如果是二维张量, 如何处理.
# 1. 创建张量, 模拟: 样本的特征
scores2 = torch.tensor([[0.2, 0.02, 0.15, 0.15], [1.3, 0.5, 0.06, 1.1]])
# 2. 计算概率, dim = 1,按列计算
probabilities2 = torch.softmax(scores2, dim=0)
# 打印结果.
print(probabilities2)
初始化参数
针对Relu 使用kaiming
针对tenh 与 sigmoid 使用 xavier
针对浅层网络 考虑随机初始化
针对于深层网络 使用kaiming
"""
案例:
演示参数初始化的写法.
目的:
神经元默认做两件事儿: 加权求和 + 激活函数
而加权求和时, 是需要 权重矩阵 和 偏置矩阵的, 模型会通过参数初始化 初始化一些值, 然后通过模型训练, 不断的优化这些值(权重矩阵, 偏置矩阵)
而我们现在学的内容就是: 模型底层怎么样去初始化 权重矩阵 和 偏置矩阵.
参数初始化如何选择:
针对于ReLU激活函数:
kaiming初始化
针对于Tanh, Sigmoid激活函数:
xavier初始化
如果是浅层网络: 考虑随机初始化
如果是深层网络: 考虑xavier初始化, kaiming初始化...
"""
# 导包
import torch
import torch.nn as nn
# todo 1. 演示均匀初始化.
def dm01_uniform_init():
# 1. 创建一个全连接层(Full Connection)
# 参1: 输入特征数(神经元个数), 参2: 输出特征数(神经元个数)
linear1 = nn.Linear(in_features=3, out_features=5) # 还有一类人会把全连接层的变量名写成: fc1
# 2. 初始化权重矩阵和偏置矩阵
nn.init.uniform_(linear1.weight) # [0, 1]区间的均匀分布
nn.init.uniform_(linear1.bias) # 看看就好, 后边不写了, 因为偏置实际开发中几乎都会设置为0(不考虑)
# 3. 打印权重矩阵和偏置矩阵
print(f'linear1.weight: {linear1.weight}')
print(f'linear1.bias: {linear1.bias}')
# todo 2. 演示正态分布初始化.
def dm02_normal_init():
# 1. 创建一个全连接层(Full Connection)
# 参1: 输入特征数(神经元个数), 参2: 输出特征数(神经元个数)
linear1 = nn.Linear(in_features=3, out_features=5) # 还有一类人会把全连接层的变量名写成: fc1
# 2. 初始化权重矩阵和偏置矩阵
nn.init.normal_(linear1.weight) # 标准差为1, 均值为0的正态分布
nn.init.normal_(linear1.bias) # 看看就好, 后边不写了, 因为偏置实际开发中几乎都会设置为0(不考虑)
# 3. 打印权重矩阵和偏置矩阵
print(f'linear1.weight: {linear1.weight}')
print(f'linear1.bias: {linear1.bias}')
# todo 3. 演示全0初始化
def dm03_zero_init():
# 1. 创建一个全连接层(Full Connection)
# 参1: 输入特征数(神经元个数), 参2: 输出特征数(神经元个数)
linear1 = nn.Linear(in_features=3, out_features=5) # 还有一类人会把全连接层的变量名写成: fc1
# 2. 初始化权重矩阵和偏置矩阵
nn.init.zeros_(linear1.weight) # 全0初始化
nn.init.zeros_(linear1.bias)
# 3. 打印权重矩阵和偏置矩阵
print(f'linear1.weight: {linear1.weight}')
print(f'linear1.bias: {linear1.bias}')
# todo 4. 演示全1初始化
def dm04_one_init():
# 1. 创建一个全连接层(Full Connection)
# 参1: 输入特征数(神经元个数), 参2: 输出特征数(神经元个数)
linear1 = nn.Linear(in_features=3, out_features=5)
# 2. 初始化权重矩阵和偏置矩阵
nn.init.ones_(linear1.weight)
nn.init.ones_(linear1.bias)
# 3. 打印权重矩阵和偏置矩阵
print(f'linear1.weight: {linear1.weight}')
print(f'linear1.bias: {linear1.bias}')
# todo 5. 演示固定值初始化.
def dm05_constant_init():
# 1. 创建一个全连接层(Full Connection)
# 参1: 输入特征数(神经元个数), 参2: 输出特征数(神经元个数)
linear1 = nn.Linear(in_features=3, out_features=5)
# 2. 初始化权重矩阵和偏置矩阵
nn.init.constant_(linear1.weight, 27)
nn.init.constant_(linear1.bias, 27)
# 3. 打印权重矩阵和偏置矩阵
print(f'linear1.weight: {linear1.weight}')
print(f'linear1.bias: {linear1.bias}')
# todo 6. 演示kaiming初始化 -> 重点掌握
def dm06_kaiming_init():
# 1. 创建一个全连接层(Full Connection)
# 参1: 输入特征数(神经元个数), 参2: 输出特征数(神经元个数)
linear1 = nn.Linear(in_features=3, out_features=5)
# 2. 初始化权重矩阵
# 思路1: 均匀分布初始化, 范围是: -sqrt(6/输入层神经元数量) ~ sqrt(6/输入层神经元数量)
# nn.init.kaiming_uniform_(linear1.weight)
# 思路2: 正态分布初始化, 均值为0, 标准差为: sqrt(2/输入层神经元数量)
nn.init.kaiming_normal_(linear1.weight)
# 3. 打印权重矩阵
print(f'linear1.weight: {linear1.weight}')
# todo 7. 掌握xavier初始化 -> 掌握
def dm07_xavier_init():
# 1. 创建一个全连接层(Full Connection)
# 参1: 输入特征数(神经元个数), 参2: 输出特征数(神经元个数)
linear1 = nn.Linear(in_features=3, out_features=5)
# 2. 初始化权重矩阵
# 思路1: 均匀分布初始化, 范围是: -sqrt(6/输入层神经元数量 + 输出层神经元数量) ~ sqrt(6/输入层神经元数量 + 输出层神经元数量)
# nn.init.xavier_uniform_(linear1.weight)
# 思路2: 正态分布初始化, 均值为0, 标准差为: sqrt(2/(输入层神经元数量 + 输出层神经元数量))
nn.init.xavier_normal_(linear1.weight)
# 3. 打印权重矩阵
print(f'linear1.weight: {linear1.weight}')
# todo 8. 测试代码
if __name__ == '__main__':
# 1. 测试: 均匀初始化
# dm01_uniform_init()
# 2. 测试: 正态分布初始化
# dm02_normal_init()
# 3. 测试: 全0初始化
# dm03_zero_init()
# 4. 测试: 全1初始化
# dm04_one_init()
# 5. 测试: 固定值初始化
# dm05_constant_init()
# 6. 测试: kaiming初始化
# dm06_kaiming_init()
# 7. 测试: xavier初始化
dm07_xavier_init()
Comments NOTHING