
概述
线性回归:用回归方程来描述 多个/1个 自变量与因变量之间关系 的一种思路
一元线性回归:y = wx+b
多元线性回归: y = T(w) * x + b
w: weight, 权重 (矩阵)/ 斜率
b:bias,偏置 / 截距
损失函数: 就是让模型效果好
误差 = 真实值 - 预测值
最小二乘:误差平方和
MAE(平均绝对误差):绝对误差的平均值,稳健。
MSE(均方误差):平方误差的平均值,放大大误差。
RMSE(均方根误差):MSE的平方根,与目标变量单位一致。
代码示例
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
import pandas as pd
def wang_Linear_train_model():
df = pd.read_csv('data/波士顿房价xy.csv')
x = df.iloc[:,:13]
y = df.iloc[:,13]
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=22)
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
model = LinearRegression()
model.fit(x_train, y_train)
y_predict = model.predict(x_test)
print(r2_score(y_test, y_predict))
if __name__ == '__main__':
wang_Linear_train_model()正则方程法
直接求解 线性回归参数 的解析方法,不迭代
梯度下降算法

梯度就是导数
沿梯度反方向迭代优化参数的方法
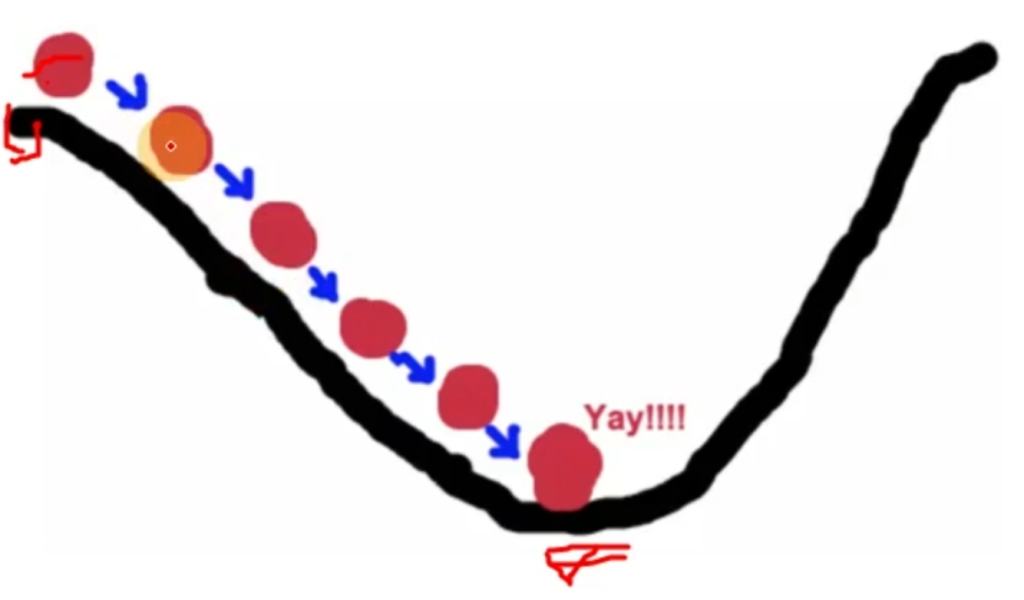
1.全梯度下降(FGD):使用全部样本的梯度值
2.随机梯度下降(SGD):随机选择一个样本的梯度值更新权重
3.小批量梯度下降(Mini-Batch):随机选择小部分样本的梯度值更新权重
4.随机平均梯度下降(SAG):使用以前产生的梯度值来指导当前的梯度计算
L1 正则化-Lasso
用于让数据稀疏 ,让模型变得简单
原因: 把多个列 变为了 0----让特征失效
Lasso(apha = 0.1)#正则化参数(惩罚力度,默认是1,值越大,权重调整就越大)
L2正则化-Ridge(常用)
也叫 岭回归
防止过拟合
让权重趋向于0 不会变为0
L2正则化:能够让模型产生一些平滑的权重系数
Early stopping 是当模型训练到某个固定的验证错误率阈值时,及时停止模型训练
L1 与 L2 正则化
相同点: 都是通过惩罚系数,调整权重的
不同点:
L1 :将权重变为0,促稀疏
L2:一般只降低权重,而不会把权重调为0
---欠拟合可以通过增加特征来解决
---过拟合可以通过正则化、异常值检测、特征降维等方法来解决
扩展:
当 SGDRegressor 的 penalty='l2' 且 loss='squared_loss' 时,其效果与岭回归相同,但仅支持随机梯度下降优化,而 Ridge 支持更多优化算法。 但 岭回归更丰富